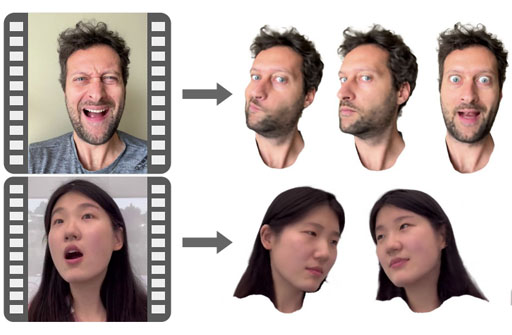
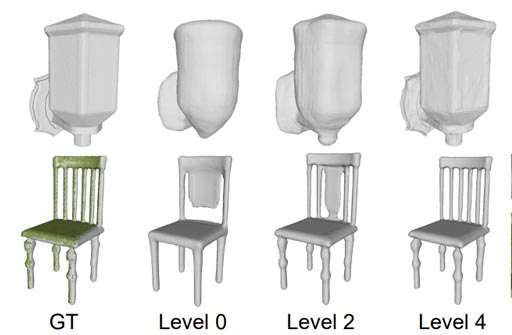
Through "Deep Learning in 3D Vision and Computer Graphics", we aim to advance research in computer graphics and 3D vision through the development of novel datasets, models, and algorithms. In SketchyScene, we developed a large-scale dataset of scene sketches for advancing research in sketch understanding and enabling several applications such as image retrieval, sketch colorization, editing, and captioning. In Language-based Colorization, we developed a language-based system for interactive colorization of scene sketches, which is more natural for novice users than scribble-based interfaces. In OmniSyn, we developed a novel pipeline for 360◦ view synthesis between wide-baseline panoramas, which is expected to produce a smoother experience for navigating immersive maps. In PRIF, we developed a new implicit shape representation called Primary Ray-based Implicit Function, enabling efficient shape extraction and differentiable rendering, and achieving successes in various tasks including shape generation, completion, and inverse rendering. In MDIF, we developed Multiresolution Deep Implicit Functions, a hierarchical representation that can recover fine geometry detail while being able to perform global operations such as shape completion, and achieving superior performance in various 3D reconstruction tasks.
Publications The International Conference on Learning Representations (ICLR), 2025.
Keywords:
Ziqian Bai ,
Feitong Tan ,
Zeng Huang ,
Kripasindhu Sarkar ,
Danhang Tang ,
Di Qiu ,
Abhimitra Meka ,
Ruofei Du ,
Mingsong Dou ,
Sergio Orts-Escolano ,
Rohit Pandey ,
Ping Tan ,
Thabo Beeler ,
Sean Fanello , and
Yinda Zhang 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
Keywords: implicit 3D avatar, monocular RGB video, facial expressions, head poses, neural radiance field, photorealism, digital human
SIGGRAPH Asia 2023 Technical Communications (SA), 2023.
Keywords: Neural rendering, Portrait expression editing, Mobile system
2022 Picture Coding Symposium (PCS), 2022.
Keywords: deep learning, image compression, nonlineartransform coding, high dynamic range, super-resolution, interactive perception
European Conference on Computer Vision (ECCV), 2022.
Keywords: deep implicit functions, neural representation, signed distance function, interactive perception, interactive graphics
2022 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), 2022.
Keywords: 360 image, virtual reality, view synthesis, panorama, neural rendering, depth map, mesh rendering, inpainting, digital world
Proceedings of the 34th Annual ACM Symposium on User Interface Software and Technology (UIST), 2021.
Keywords: eye contact, gaze awareness, video conferencing, video-mediated communication, gaze interaction, augmented communication, augmented conversation, eye tracking, XR interaction
2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
Keywords: deep implicit functions, neural representation, compression, levels of detail, MDIF, interactive perception
Feitong Tan ,
Danhang Tang ,
Mingsong Dou ,
Kaiwen Guo ,
Rohit Pandey ,
Cem Keskin ,
Ruofei Du ,
Deqing Sun ,
Sofien Bouaziz ,
Sean Fanello ,
Ping Tan , and
Yinda Zhang 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
Keywords: correspondences, geodesic distance, embeddings, neural networks, digital human, interactive perception
2021 IEEE International Conference on Image Processing (ICIP), 2021.
Keywords: deep learning, image compression, interactive perception
ACM Transactions on Graphics (SIGGRAPH Asia), 2019.
Keywords: deep neural networks; image segmentation; language-based editing; scene sketch; sketch colorization, interactive graphics, interactive perception, augmented communication
European Conference on Computer Vision (ECCV), 2018.
Keywords: sketch dataset, scene sketch, sketch segmentation, interactive graphics
Cited By I Cannot See Students Focusing on My Presentation; Are They Following Me? Continuous Monitoring of Student Engagement Through "Stungage" arXiv.2204.08193. Snigdha Das , Sandip Chakraborty , and Bivas Mitra . source | cite | search Sketch-Based Creativity Support Tools Using Deep Learning Artificial Intelligence for Human Computer Interaction: A Modern Approach. Forrest Huang , Eldon Schoop , David Ha , Jeffrey Nichols , and John Canny . source | cite | search Dance in the Wild: Monocular Human Animation with Neural Dynamic Appearance Synthesis https://arxiv.org/pdf/2111.05916.pdf. Tuanfeng Y. Wang , Duygu Ceylan , Krishna Kumar Singh , and Niloy J. Mitra . source | cite | search Emergent Graphical Conventions in a Visual Communication Game https://arxiv.org/pdf/2111.14210.pdf. Shuwen Qiu , Sirui Xie , Lifeng Fan , Tao Gao , Song-Chun Zhu , and Yixin Zhu . source | cite | search Write-an-Animation: High-level Text-based Animation Editing with Character-Scene Interaction Computer Graphics Forum. Jia-Qi Zhang , Xiang Xu , Zhi-Meng Shen , Ze-Huan Huang , Yang Zhao , Yan-Pei Cao , Pengfei Wan , and Miao Wang . source | cite | search BACON: Band-limited Coordinate Networks for Multiscale Scene Representation https://arxiv.org/pdf/2112.04645.pdf. David B. Lindell , Dave Van Veen , Jeong Joon Park , and Gordon Wetzstein . source | cite | search UNIST: Unpaired Neural Implicit Shape Translation Network https://arxiv.org/pdf/2112.05381.pdf. Qimin Chen , Johannes Merz , Aditya Sanghi , Hooman Shayani , Ali Mahdavi-Amiri , and Hao Zhang . source | cite | search One Sketch for All: One-Shot Personalized Sketch Segmentation https://arxiv.org/pdf/2112.10838.pdf. Anran Qi , Yulia Gryaditskaya , Tao Xiang , and Yi-Zhe Song . source | cite | search Human View Synthesis Using a Single Sparse RGB-D Input arXiv.2112.13889. Phong Nguyen , Nikolaos Sarafianos , Christoph Lassner , Janne Heikkila , and Tony Tung . source | cite | search PINs: Progressive Implicit Networks for Multi-Scale Neural Representations https://arxiv.org/pdf/2202.04713.pdf. Zoe Landgraf , Alexander Sorkine Hornung , and Ricardo Silveira Cabral . source | cite | search FS-COCO: Towards Understanding of Freehand Sketches of Common Objects in Context https://arxiv.org/pdf/2203.02113.pdf. Pinaki Nath Chowdhury , Aneeshan Sain , Yulia Gryaditskaya , Ayan Kumar Bhunia , Tao Xiang , and Yi-Zhe Song . source | cite | search BodyMap: Learning Full-Body Dense Correspondence Map arXiv.2205.09111. Anastasia Ianina , Nikolaos Sarafianos , Yuanlu Xu , Ignacio Rocco , and Tony Tung . source | cite | search Delaunay Painting: Perceptual Image Colouring From Raster Contours with Gaps Computer Graphics Forum. Amal Dev Parakkat , Pooran Memari , and Marie-Paule Cani . source | cite | search SceneSketcher-v2: Fine-Grained Scene-Level Sketch-Based Image Retrieval Using Adaptive GCNs IEEE Transactions on Image Processing. Fang Liu , Xiaoming Deng , Changqing Zou , Yu-Kun Lai , Keqi Chen , Ran Zuo , Cuixia Ma , Yong-Jin Liu , and Hongan Wang . source | cite | search 3DILG: Irregular Latent Grids for 3D Generative Modeling arXiv.2205.13914. Biao Zhang , Matthias Nießner , and Peter Wonka . source | cite | search PatchComplete: Learning Multi-Resolution Patch Priors for 3D Shape Completion on Unseen Categories arXiv.2206.04916. Yuchen Rao , Yinyu Nie , and Angela Dai . source | cite | search Preprocessing Enhanced Image Compression for Machine Vision arXiv.2206.05650. Guo Lu , Xingtong Ge , Tianxiong Zhong , Jing Geng , and Qiang Hu . source | cite | search A Review of Image and Video Colorization: From Analogies to Deep Learning Visual Informatics. Shu-Yu Chen , Jia-Qi Zhang , You-You Zhao , Paul L. Rosin , Yu-Kun Lai , and Lin Gao . source | cite | search Exemplar-Based Sketch Colorization with Cross-Domain Dense Semantic Correspondence Mathematics. Jinrong Cui , Haowei Zhong , Hailong Liu , and Yulu Fu . source | cite | search Neural Image Recolorization for Creative Domains 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Boyi Li , Serge Belongie , Ser-nam Lim , and Abe Davis . source | cite | search SketchMaker: Sketch Extraction and Reuse for Interactive Scene Sketch Composition ACM Transactions on Interactive Intelligent Systems. Fang Liu , Xiaoming Deng , Jiancheng Song , Yu-Kun Lai , Yong-Jin Liu , Hao Wang , Cuixia Ma , Shengfeng Qin , and Hongan Wang . source | cite | search PatchRD: Detail-Preserving Shape Completion by Learning Patch Retrieval and Deformation arXiv.2207.11790. Bo Sun , Vladimir G. Kim , Noam Aigerman , Qixing Huang , and Siddhartha Chaudhuri . source | cite | search Local Free-View Neural 3D Head Synthesis for Virtual Group Meetings 2022 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW). Sebastian Rings and Frank Steinicke . source | cite | search Augmented Chironomia for Presenting Data to Remote Audiences arXiv.2208.04451. Brian D. Hall , Lyn Bartram , and Matthew Brehmer . source | cite | search A State of the Art and Scoping Review of Embodied Information Behavior in Shared, Co-present Extended Reality Experiences Electronic Imaging. Kathryn Hays , Arturo Barrera , Lydia Ogbadu-Oladapo , Olumuyiwa Oyedare , Julia Payne , Mohotarema Rashid , Jennifer Stanley , Lisa Stocker , Christopher Lueg , Michael Twidale , and Ruth West . source | cite | search Progressive Multi-scale Light Field Networks arXiv.2208.06710. David Li and Amitabh Varshney . source | cite | search Modulating Bottom-Up and Top-Down Visual Processing Via Language-Conditional Filters 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Ilker Kesen , Ozan Arkan Can , Erkut Erdem , Aykut Erdem , and Deniz Yuret . source | cite | search Unsupervised Scene Sketch to Photo Synthesis arXiv.2209.02834. Jiayun Wang , Sangryul Jeon , Stella X. Yu , Xi Zhang , Himanshu Arora , and Yu Lou . source | cite | search Cartoon Image Processing: A Survey International Journal of Computer Vision. Yang Zhao , Diya Ren , Yuan Chen , Wei Jia , Ronggang Wang , and Xiaoping Liu . source | cite | search Free-Viewpoint RGB-D Human Performance Capture and~Rendering Lecture Notes in Computer Science. Phong Nguyen-Ha , Nikolaos Sarafianos , Christoph Lassner , Janne Heikkilä , and Tony Tung . source | cite | search DrawMon: A Distributed System for Detection of Atypical Sketch Content in Concurrent Pictionary Games Proceedings of the 30th ACM International Conference on Multimedia. Nikhil Bansal , Kartik Gupta , Kiruthika Kannan , Sivani Pentapati , and Ravi Kiran Sarvadevabhatla . source | cite | search VoLux-GAN: A Generative Model for 3D Face Synthesis with HDRI Relighting Special Interest Group on Computer Graphics and Interactive Techniques Conference Proceedings. Feitong Tan , Sean Fanello , Abhimitra Meka , Sergio Orts-Escolano , Danhang Tang , Rohit Pandey , Jonathan Taylor , Ping Tan , and Yinda Zhang . source | cite | search Machine Learning for Multimedia Communications Sensors. Nikolaos Thomos , Thomas Maugey , and Laura Toni . source | cite | search Pri3D: Can 3D Priors Help 2D Representation Learning? https://arxiv.org/abs/2104.11225.pdf. Ji Hou , Saining Xie , Benjamin Graham , Angela Dai , and M. Nießner . source | cite | search Generating Compositional Color Representations From Text https://arxiv.org/abs/2109.10477. Paridhi Maheshwari , Nihal Jain , Praneetha Vaddamanu , Dhananjay Raut , Shraiysh Vaishay , and Vishwa Vinay . source | cite | search Painting Style-Aware Manga Colorization Based on Generative Adversarial Networks 2021 IEEE International Conference on Image Processing (ICIP). Yugo Shimizu , Ryosuke Furuta , Delong Ouyang , Yukinobu Taniguchi , Ryota Hinami , and Shonosuke Ishiwatari . source | cite | search Adversarial Segmentation Loss for Sketch Colorization 2021 IEEE International Conference on Image Processing (ICIP). Samet Hicsonmez , Nermin Samet , Emre Akbas , and Pinar Duygulu . source | cite | search Focusing on Persons 4. Xin Jin , Zhonglan Li , Ke Liu , Dongqing Zou , Xiaodong Li , Xingfan Zhu , Ziyin Zhou , Qilong Sun , and Qingyu Liu . source | cite | search Sketchy Scene Captioning: Learning Multi-level Semantic Information From Sparse Visual Scene Cues Lecture Notes in Computer Science. Lian Zhou , Yangdong Chen , and Yuejie Zhang . source | cite | search Multi-style Chinese Art Painting Generation of Flowers IET Image Processing. Feifei Fu , Jiancheng Lv , Chenwei Tang , and Mao Li . source | cite | search TediGAN: Text-Guided Diverse Face Image Generation and Manipulation Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Weihao Xia , Yujiu Yang , Jing-Hao Xue , and Baoyuan Wu . source | cite | search DanbooRegion: An Illustration Region Dataset Computer Vision –ECCV 2020. Lvmin Zhang , Yi Ji , and Chunping Liu . source | cite | search SketchyDepth: From Scene Sketches to RGB-D Images ICCV 2021. Gianluca Berardi , Samuele Salti , and Luigi Di Stefano . source | cite | search Generative Adversarial Networks\textendashEnabled Human\textendashArtificial Intelligence Collaborative Applications for Creative and Design Industries: A Systematic Review of Current Approaches and Trends Frontiers in Artificial Intelligence. Rowan T. Hughes , Liming Zhu , and Tomasz Bednarz . source | cite | search XCI-Sketch: Extraction of Color Information From Images for Generation of Colored Outlines and Sketche https://arxiv.org/abs/2108.11554. Harsh Rathod , Manisimha Varma , Parna Chowdhury , Sameer Saxena , V. Manushree , Ankita Ghosh , and Sahil Khose . source | cite | search Generating Compositional Color Representations From Text https://arxiv.org/abs/2109.10477. Paridhi Maheshwari , Nihal Jain , Praneetha Vaddamanu , Dhananjay Raut , Shraiysh Vaishay , and Vishwa Vinay . source | cite | search Text As Neural Operator:Image Manipulation by Text Instruction MM '21: Proceedings of the 29th ACM International Conference on Multimedia. Tianhao Zhang , Hung-Yu Tseng , Lu Jiang , Weilong Yang , Honglak Lee , and Irfan Essa . source | cite | search DLA-Net for FG-SBIR 5. Jiaqing Xu , Haifeng Sun , Qi Qi , Jingyu Wang , Ce Ge , Lejian Zhang , and Jianxin Liao . source | cite | search Grayscale Image Colorization Using a Convolutional Neural Network Journal of the Korean Society for Industrial and Applied Mathematics. Minje Jwa and Myungjoo Kang . source | cite | search Exploring Local Detail Perception for Scene Sketch Semantic Segmentation IEEE Transactions on Image Processing. Ce Ge , Haifeng Sun , Yi-Zhe Song , Zhanyu Ma , and Jianxin Liao . source | cite | search Learning Deep Implicit Functions for 3D Shapes with Dynamic Code Clouds https://arxiv.org/abs/2203.14048. Tianyang Li , Xin Wen , Yu-Shen Liu , Hua Su , and Zhizhong Han . source | cite | search Towards Implicit Text-Guided 3D Shape Generation https://arxiv.org/abs/2203.14622. Zhengzhe Liu , Yi Wang , Xiaojuan Qi , and Chi-Wing Fu . source | cite | search Versatile Multi-Modal Pre-Training for Human-Centric Perception arXiv.2203.13815. Fangzhou Hong , Liang Pan , Zhongang Cai , and Ziwei Liu . source | cite | search Partially Does It: Towards Scene-Level FG-SBIR with Partial Input arXiv.2203.14804. Pinaki Nath Chowdhury , Ayan Kumar Bhunia , Viswanatha Reddy Gajjala , Aneeshan Sain , Tao Xiang , and Yi-Zhe Song . source | cite | search Supplementary for “Learning Deep Implicit Functions for 3D Shapes with Dynamic Code Clouds” https://arxiv.org/abs/2203.14048. Tianyang Li , Xin Wen , Yu-Shen Liu , Hua Su , and Zhizhong Han . source | cite | search ShapeFormer: Transformer-based Shape Completion Via Sparse Representation arXiv.2201.10326. Xingguang Yan , Liqiang Lin , Niloy J. Mitra , Dani Lischinski , Daniel Cohen-Or , and Hui Huang . source | cite | search ColorizeDiffusion: Adjustable Sketch Colorization with Reference Image and Text arXiv.2401.01456. Dingkun Yan , Liang Yuan , Yuma Nishioka , Issei Fujishiro , and Suguru Saito . source | cite | search OpenSketch: A Richly-annotated Dataset of Product Design Sketches ACM Transactions on Graphics. Yulia Gryaditskaya , Mark Sypesteyn , Jan Willem Hoftijzer , Sylvia Pont , Frédo Dur , and Adrien Bousseau . source | cite | search Language-based Photo Color Adjustment for Graphic Designs ACM Transactions on Graphics. Zhenwei Wang , Nanxuan Zhao , Gerhard Hancke , and Rynson W.H. Lau . source | cite | search Semi-supervised Reference-based Sketch Extraction Using a Contrastive Learning Framework ACM Transactions on Graphics. Chang Wook Seo , Amirsaman Ashtari , and Junyong Noh . website , source | cite | search OpenMic: Utilizing Proxemic Metaphors for Conversational Floor Transitions in Multiparty Video Meetings Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. Erzhen Hu , Jens Emil Sloth Gr{\o}nb{\ae}k , Austin Houck , and Seongkook Heo . source | cite | search ViGather: Inclusive Virtual Conferencing with a Joint Experience Across Traditional Screen Devices and Mixed Reality Headsets Proceedings of the ACM on Human-Computer Interaction. Huajian Qiu , Paul Streli , Tiffany Luong , Christoph Gebhardt , and Christian Holz . source | cite | search Stroke-based Semantic Segmentation for Scene-level Free-hand Sketches The Visual Computer. Zhengming Zhang , Xiaoming Deng , Jinyao Li , Yukun Lai , Cuixia Ma , Yongjin Liu , and Hongan Wang . source | cite | search A Reference Framework for Evaluating Virtual Conferences/submitted by Alexander Gindlhumer JOHANNES KEPLER UNIVERSITY LINZ. Alexander Gindlhumer . source | cite | search Differentiable Bit-rate Estimation for Neural-based Video Codec Enhancement 2022 Picture Coding Symposium (PCS). Amir Said , Manish Kumar Singh , and Reza Pourreza . source | cite | search Differentiable Bit-rate Estimation for Neural-based Video Codec Enhancement 2022 Picture Coding Symposium (PCS). Amir Said , Manish Kumar Singh , and Reza Pourreza . source | cite | search iBall: Augmenting Basketball Videos with Gaze-moderated Embedded Visualizations Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. Zhutian Chen , Qisen Yang , Jiarui Shan , Tica Lin , Johanna Beyer , Haijun Xia , and Hanspeter Pfister . source | cite | search NeuRBF: A Neural Fields Representation with Adaptive Radial Basis Functions arXiv.2309.15426. Zhang Chen , Zhong Li , Liangchen Song , Lele Chen , Jingyi Yu , Junsong Yuan , and Yi Xu . source | cite | search Tiled Multiplane Images for Practical 3D Photography arXiv.2309.14291. Numair Khan , Douglas Lanman , and Lei Xiao . source | cite | search A Reference Framework for Evaluating Virtual Conferences Universitätsbibliothek Linz. Lisa-Marie Huber and Alexander Gindlhumer . source | cite | search Deep Learning for Studying Drawing Behavior: A Review Frontiers in Psychology. Benjamin Beltzung , Marie Pel{\'{e}} , Julien P. Renoult , and C{\'{e}}dric Sueur . source | cite | search Human\textendashmachine Hybrid Intelligence for the Generation of Car Frontal Forms Advanced Engineering Informatics. Yu Wu , Lisha Ma , Xiaofang Yuan , and Qingnan Li . source | cite | search Learnt Deep Hyperparameter Selection in Adversarial Training for Compressed Video Enhancement with a Perceptual Critic 2023 IEEE International Conference on Image Processing (ICIP). Darren Ramsook and Anil Kokaram . source | cite | search Controllable Mesh Generation Through Sparse Latent Point Diffusion Models arXiv.2303.07938. Zhaoyang Lyu , Jinyi Wang , Yuwei An , Ya Zhang , Dahua Lin , and Bo Dai . source | cite | search DisETrac: Distributed Eye-Tracking for Online Collaboration Proceedings of the 2023 Conference on Human Information Interaction and Retrieval. Bhanuka Mahanama , Mohan Sunkara , Vikas Ashok , and Sampath Jayarathna . source | cite | search SVCNet: Scribble-based Video Colorization Network with Temporal Aggregation arXiv.2303.11591. Yuzhi Zhao , Lai-Man Po , Kangcheng Liu , Xuehui Wang , Wing-Yin Yu , Pengfei Xian , Yujia Zhang , and Mengyang Liu . source | cite | search Sandwiched Video Compression: Efficiently Extending the Reach of Standard Codecs with Neural Wrappers arXiv.2303.11473. Berivan Isik , Onur Guleryuz , Danhang Tang , Jonathan Taylor , and Philip Chou . source | cite | search Adversarial Interactive Cartoon Sketch Colourization with Texture Constraint and Auxiliary Auto-Encoder Computer Graphics Forum. Xiaoyu Liu , Shaoqiang Zhu , Yao Zeng , and Junsong Zhang . source | cite | search VVC+M: Plug and Play Scalable Image Coding for Humans and Machines arXiv.2305.10453. Alon Harell , Yalda Foroutan , and Ivan V. Bajic . source | cite | search Fine-Grained Video Retrieval with Scene Sketches IEEE Transactions on Image Processing. Ran Zuo , Xiaoming Deng , Keqi Chen , Zhengming Zhang , Yu-Kun Lai , Fang Liu , Cuixia Ma , Hao Wang , Yong-Jin Liu , and Hongan Wang . source | cite | search An End-to-End Review of Gaze Estimation and Its Interactive Applications on Handheld Mobile Devices ACM Computing Surveys. Yaxiong Lei , Shijing He , Mohamed Khamis , and Juan Ye . source | cite | search PanoGRF: Generalizable Spherical Radiance Fields for Wide-baseline Panoramas arXiv.2306.01531. Zheng Chen , Yan-Pei Cao , Yuan-Chen Guo , Chen Wang , Ying Shan , and Song-Hai Zhang . source | cite | search Normal-guided Garment UV Prediction for Human Re-Texturing arXiv.2303.06504. Yasamin Jafarian , Tuanfeng Y. Wang , Duygu Ceylan , Jimei Yang , Nathan Carr , Yi Zhou , and Hyun Soo Park . source | cite | search LoRD: Local 4D Implicit Representation for High-Fidelity Dynamic Human Modeling arXiv.2208.08622. Boyan Jiang , Xinlin Ren , Mingsong Dou , Xiangyang Xue , Yanwei Fu , and Yinda Zhang . source | cite | search CallMap: A Multi-dialogue Participative Chatting Environment Based on~Participation Structure Lecture Notes in Computer Science. Masanari Ichikawa and Yugo Takeuchi . source | cite | search A State-of-Art Review on~Intelligent Systems for~Drawing Assisting Lecture Notes in Computer Science. Juexiao Qin , Xiaohua Sun , and Weijian Xu . source | cite | search Pseudo-mutual Gazing Enhances Interbrain Synchrony During Remote Joint Attention Tasking Brain and Behavior. Chun-Hsiang Chuang and Hao-Che Hsu . source | cite | search MARF: The Medial Atom Ray Field Object Representation Computers & Graphics. Peder Bergebakken Sundt and Theoharis Theoharis . source | cite | search Improving Sketch Colorization Using Adversarial Segmentation Consistency arXiv.2301.08590. Samet Hicsonmez , Nermin Samet , Emre Akbas , and Pinar Duygulu . source | cite | search Visual Coding for Machines Simon Fraser University. Bardia Azizian . source | cite | search TMSDNet: Transformer with Multi-scale Dense Network for Single and Multi-view 3D Reconstruction Computer Animation and Virtual Worlds. Xiaoqiang Zhu , Xinsheng Yao , Junjie Zhang , Mengyao Zhu , Lihua You , Xiaosong Yang , Jianjun Zhang , He Zhao , and Dan Zeng . source | cite | search Grid-guided Neural Radiance Fields for Large Urban Scenes arXiv.2303.14001. Linning Xu , Yuanbo Xiangli , Sida Peng , Xingang Pan , Nanxuan Zhao , Christian Theobalt , Bo Dai , and Dahua Lin . source | cite | search Text2shape Deep Retrieval Model: Generating Initial Cases for Mechanical Part Redesign Under the Context of Case-Based Reasoning arXiv.2302.06341. Tianshuo Zang , Maolin Yang , Wentao Yong , and Pingyu Jiang . source | cite | search Ponder : Point Cloud Pre-training Via Neural Rendering arXiv.2301.00157. Di Huang , Sida Peng , Tong He , Xiaowei Zhou , and Wanli Ouyang . source | cite | search OReX: Object Reconstruction From Planner Cross-sections Using Neural Fields arXiv.2211.12886. Haim Sawdayee , Amir Vaxman , and Amit H. Bermano . source | cite | search ConVol-E: Continuous Volumetric Embeddings for Human-Centric Dense Correspondence Estimation 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Amogh Tiwari , Pranav Manu , Nakul Rathore , Astitva Srivastava , and Avinash Sharma . source | cite | search FPM-INR: Fourier Ptychographic Microscopy Image Stack Reconstruction Using Implicit Neural Representations arXiv.2310.18529. Haowen Zhou , Brandon Feng , Haiyun Guo , Siyu Lin , Mingshu Liang , Christopher A. Metzler , and Changhuei Yang . source | cite | search Reconstructive Latent-Space Neural Radiance Fields for Efficient 3D Scene Representations arXiv.2310.17880. Tristan Aumentado-Armstrong , Ashkan Mirzaei , Marcus A. Brubaker , Jonathan Kelly , Alex Levinshtein , Konstantinos G. Derpanis , and Igor Gilitschenski . source | cite | search RayDF: Neural Ray-surface Distance Fields with Multi-view Consistency arXiv.2310.19629. Zhuoman Liu and Bo Yang . source | cite | search ConVRT: Consistent Video Restoration Through Turbulence with Test-time Optimization of Neural Video Representations arXiv.2312.04679. Haoming Cai , Jingxi Chen , Brandon Feng , Weiyun Jiang , Mingyang Xie , Kevin Zhang , Ashok Veeraraghavan , and Christopher Metzler . source | cite | search Advances in 3D Generation: A Survey arXiv.2401.17807. Xiaoyu Li , Qi Zhang , Di Kang , Weihao Cheng , Yiming Gao , Jingbo Zhang , Zhihao Liang , Jing Liao , Yan-Pei Cao , and Ying Shan . source | cite | search Adapting Learned Image Codecs to Screen Content Via Adjustable Transformations arXiv.2402.17544. H. Burak Dogaroglu , A. Burakhan Koyuncu , Atanas Boev , Elena Alshina , and Eckehard Steinbach . source | cite | search CustomSketching: Sketch Concept Extraction for Sketch-based Image Synthesis and Editing arXiv.2402.17624. Chufeng Xiao and Hongbo Fu . source | cite | search Learning Inclusion Matching for Animation Paint Bucket Colorization arXiv.2403.18342. Yuekun Dai , Shangchen Zhou , Qinyue Li , Chongyi Li , and Chen Change Loy . source | cite | search CreativeSeg: Semantic Segmentation of Creative Sketches IEEE Transactions on Image Processing. Yixiao Zheng , Kaiyue Pang , Ayan Das , Dongliang Chang , Yi-Zhe Song , and Zhanyu Ma . source | cite | search Gazing Heads: Investigating Gaze Perception in Video-Mediated Communication ACM Transactions on Computer-Human Interaction. Martin Schuessler , Luca Hormann , Raimund Dachselt , Andrew Blake , and Carsten Rother . source | cite | search TGAvatar: Reconstructing 3D Gaussian Avatars with Transformer-based Tri-Plane IEEE Transactions on Circuits and Systems for Video Technology. Ruigang Hu , Xuekuan Wang , Yichao Yan , and Cairong Zhao . source | cite | search Ponder : Point Cloud Pre-training Via Neural Rendering arXiv.2301.00157. Di Huang , Sida Peng , Tong He , Xiaowei Zhou , and Wanli Ouyang . source | cite | search 3D Motion Magnification: Visualizing Subtle Motions with Time Varying Radiance Fields arXiv.2308.03757. Brandon Feng , Hadi Alzayer , Michael Rubinstein , William Freeman , and Jia-Bin Huang . source | cite | search